Few weeks ago, I got an idea to implement an interesting feature in DotVVM – the Server-side viewmodel caching. It can have a huge impact on a performance of DotVVM applications as it can reduce the data transferred on postback to almost nothing.
Intro – the basic principles of DotVVM
The idea behind DotVVM was quite simple – we want to use MVVM for building web applications, and we want to write in C#.
That’s why the viewmodel in DotVVM is a C# class and lives on the server where .NET runtime is. In order to have client-side interactivity in the web page, the viewmodel needs to operate on the client-side. Therefore, DotVVM serializes the viewmodel into JSON and includes it with the page HTML.
When the page is loaded, the client-side library of DotVVM will parse the JSON and create a Knockout JS instance of the viewmodel. Thanks to this, the DotVVM controls can use the Knockout data-bind attributes to offer their functionality. DotVVM just translates <dot:TextBox> to <input data-bind=”…” /> to make it working.
When the user decides to click a button, there is a method that needs to be called. However, this method lies on the server. DotVVM has to take the Knockout JS viewodel, serialize it and send it to the server, where it is deserialized so the method has the all the data and state that it needs to run. After the method completes, the viewmodel is serialized again and sent to the client where it is applied to the Knockout JS instance of the viewmodel and all controls in the page are updated.
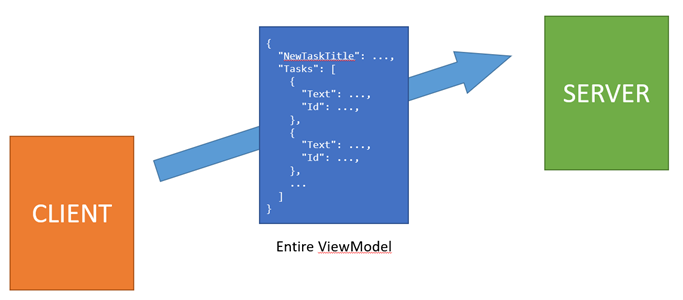

The entire process involves transferring the viewmodel from the server to the client and back. The response to the postback is efficient in general as it doesn’t need to transfer the entire viewmodel. The server compares the current viewmodel with the version received from the client, and sends only the changes.
But because of the stateless nature of DotVVM, the client has to send the entire viewmodel to the server. Or had, to be precise, because this now changes with the Server-side viewmodel caching.
DotVVM offers several mechanisms to prevent the entire viewmodel to be transferred:
- The Bind attribute can specify the direction in which the data will be transferred.
- The Static Commands allow to call a method, pass it any arguments and update the viewmodel with the result returned from the call.
- REST API bindings can load additional data from a REST API which are not considered as a part of the viewmodel and therefore are not transferred on postbacks.
However, each method has some limitations and is more difficult to use. The comfort of using Command Binding which triggers a full postback is very tempting.
What about storing the viewmodel on the server?
The reason for sending the entire viewmodel on the server is simple – the viewmodel is not stored anywhere. When the server completes the HTTP request and sends the viewmodel to the client, it forgets about it immediately.
The server-side caching feature will change this behavior – the viewmodel will be kept on the server (in a JSON-serialized form, so the live object with dependencies to various application services could be garbage-collected) and the client will send only the diff on postback.
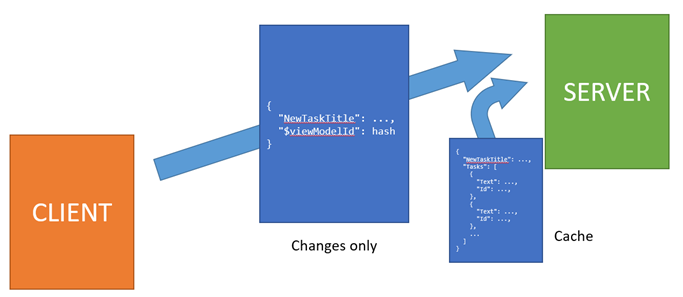
Storing the viewmodel on the server introduces several challenges:
- It will require more server resources. The viewmodels are not large in general (the average size is 1-15 kB based on the complexness of the page) and they can be compressed thanks to their text-based nature.
- It can make DOS attacks easier it an attacker finds a way to exhaust server resources.
- When the application is hosted on a web farm, the cache must be distributed.
- What about cache synchronization in case of multiple postbacks?
- Is the cache worth the troubles at all?
During our use of DotVVM on customer projects, we have made several observations:
- When DotVVM is used on a public-facing websites, the viewmodels are tiny and mostly static. It is very frequent that all HTTP GET requests have the same viewmodel and it changes only then the user interacts with the page (e.g. enters a value in a textbox).
- When DotVVM is used in line of business applications with many GridView controls, the most of the viewmodel is occupied by the contents of the GridView. If the user doesn’t use the inline edit functionality, the GridView is read-only and there is not much value in transferring its contents back to the server – the server can retrieve the most current data from the database.
It is obvious that the server-side caching will not help much in the first case, however it will help a lot in the second case.
Imagine a page with a GridView control with many rows. Each row will contain a button that can delete the particular row.
The viewmodel will contain a collection of objects representing each row. The data are read-only and thus cannot change. When the delete button is clicked, the viewmodel doesn’t need to be transferred to the server at all – we have saved almost 100%.
There is still some metadata that need to be transferred, like the cached viewmodel ID, CSRF token, and also the encrypted and protected values are excluded from the caching mechanism. But this data are relatively small in comparison to the GridView data.
Even if the user decides to use the inline editing functionality and updates a particular row, only the changes made in the viewmodel will be transferred. If there was 50 rows and one was changed, we can save about 98% of the data.
The viewmodels have 1 to 15kBs in average, so it’s not such a big deal, but still, when you multiply it by the number of concurrent users, or consider the users using a cellular networks, the difference can be quite significant.
Deduplication of cache entries
The observation for public-facing websites mentioned in the previous section brings another challenge – imagine there are thousands of users visiting the website. Most of them will leave immediately without making any postback, or they will just browse a few pages without any other of interaction that would trigger the postback.
As was mentioned before, the viewmodels in this case can be static. They will contain a few values that are used by the page, but their values will be the same when the page is loaded.
Imagine a page with a contact form. The viewmodel will contain properties for the subject, message contents and reply e-mail address, but they will be empty unless the user change them.
That’s why we’ve decided to use a hash of the viewmodel as the cache key. These pages will not exhaust the cache with thousands of equal entries because they will get the same key. This will allow to have just one cache entry for each page that will be shared between all its users (unless they change something and make a postback).
The encrypted and protected values are excluded from the caching mechanism, so it should not bring any security issue. When the user changes the viewmodel, it will get a different hash and will be stored in a separate cache entry.
Can the cache entry expire?
Of course it can. Most of us have probably had issues with expired sessions. But thankfully, this will not be the case of DotVVM. We always have the most current viewmodel on the client, so when the postback is sent and the server cannot find the viewmodel in cache, it will respond that there is a cache miss. In this case, DotVVM will automatically make an additional (full) postback sending the entire viewmodel to the server. Unless the authentication cookie is still valid, the postback will be performed – it will be just a little slower than usual.
The problem is now reduced in fine-tuning the cache settings – choosing a good compromise between the lifetime of the cached viewmodels and the cache size (and a proper storage – it may not be efficient to store the data in-memory).
It will take a lot of measurements and probably creating some tools which can help with making informed decisions on how to set up the cache correctly.
Can I try it now?
Not yet, but very soon. I have just added a new API for turning on experimental features. But in the next preview release of DotVVM, there will be an option to turn this feature on globally, or only for a specific pages.